Uncertainty is one of these buzzwords that you hear thrown around when people talk about using deep learning in their production systems: The system should provide some kind of measure of how certain it is of its judgements. I am specifically talking about systems here, since it is unlikely to simply use a deep neural network in an end-to-end fashion. What most people unfortunately skip is to actually tell you what uncertainty means (to them or in general), which is why I’d like to discuss some aspects of it here.
A Practical Notion of Uncertainty
A first approach to define uncertainty might be as follows: For an input image, we want not only its class, but also the probability that this classification is correct. Uncertainty is one minus that probability. This begs the question how that probability is to be interpreted: Under a frequentist interpretation, we would expect that a classification with probability \(p\) is correct \(p\) percent of the time (it thus should reflect the accuracy of the network). This is the definition of uncertainty that I think many people working with deep learning in a non-academic environment have in mind. This perspective has already been explored and usually comes with a different name:
Model Calibration
A network is calibrated if the scores output by its softmax-layer are probabilities in the above sense, i.e. that a class predicted with weight \(p\) is correct \(p\) percent of the time. If you haven’t taken any measures to ensure that you network is calibrated, you will most likely find that it is somewhat overconfident, meaning that it will overestimate its own accuracy. Usually, calibration is shown with a calibration plot where accuracy is plotted against the softmax-output (note that all classes are considered here, not just the one with the highest activation). Perfect calibration manifests itself as a diagonal in the plots.
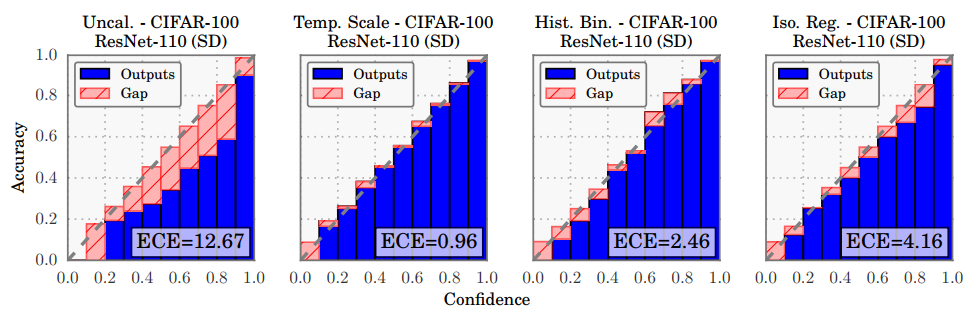
Image taken from On Calibration of Modern Neural Networks.
In the figure above, you can see calibration plots for an uncalibrated network (left most plot) and calibrated versions using three different methods along with their expected calibration error (ECE), a measure of miscalibration. See Guo et al., 2017 for the methods used for calibration.
The phenomenon of over-confidence is mostly found in large neural networks. Smaller networks are often well-calibrated. A fun experiment is to construct a very small network for 2-class classification, train it with random noise labeled with Bernoulli distributed labels (i.e., there shouldn’t be any signal in the data beyond the base probabilities for the two classes), and look at its softmax-outputs: You will find that by varying the parameter of the Bernoulli distribution, you can effectively control the softmax-activation such that it reflects the base line probabilities for the two classes.
So calibrated networks is what we want, right? Well, yes, but that’s not enough. The network must be calibrated relative to some dataset (most likely a test set that is assumed to be drawn from the same distribution as our training data) and outside of data that also follows the distribution of that dataset, the network’s outputs are essentially unconstrained1 and we have no idea whether the network is calibrated for that. Who knows what your network trained to distinguish pictures of cats from pictures of dogs will output when presented with a picture of an elephant? For that same reason any such measure that is learnt from the data is doomed from the beginning.
Detecting Out-of-Distribution Inputs
With that said, it seems like it would be sufficient to develop a method that can detect samples that are unlike any of the training samples (or have a low probability under the assumed distribution of the training data). There are a few methods for doing this; most of them follow the scheme of first training your model and then fitting a simple distribution to some measure derived from the representation of the training data in the network (see e.g. Bendale & Boult, 2015).
As a simplistic example, you could fit a Gaussian to some pre-softmax activation for each of your classes and reject a new input sample as out-of-distribution when its activations are beyond three standard deviations for each of your learned distributions. I see two problems with this approach: First, the assumption that the distribution of the representation of your training data can be captured by something as simple as, say, a Gaussian seems unreasonable. Secondly, this still doesn’t really solve the problem because there is no guarantee that your network doesn’t also map all kind of bogus inputs to the exact same representation as a perfectly fine training sample. This approach is taken to the extreme in Hendrycks & Gympel, 2016 where they are only looking on the maximum softmax scores and note that these are generally higher for correctly classified samples than for incorrectly classified and out-out-distribution samples. Thresholding is then used to make the final decision. Admittedly, their approach works, but I feel that it has no right to work: It’s taking advantage of an artifact of the training and is generally not satisfying. This approach has been improved on in Liang et al., 20172.
Alternatively, there are learning based approaches that try to learn the input distribution in some unsupervised fashion. Two ideas immediately come to mind: Using the reconstruction error of an autoencoder and using the decision of the discriminator network of a GAN to find out-of-distribution samples. Both avenues have been explored; see Spigler, 2017 for the autoencoder case.
Another approach that I liked is from Kardan & Stanley, 2016. Their architecture seems to be inspired by ensembles (i.e. fitting multiple models to your data and using all of their predictions for your final decision), but doesn’t come with the cost of running multiple models. Instead of using a single output unit in the softmax layer per class, they give each class \(\omega\) many units, such that the softmax is computed over \(\omega \times c\) units, where \(c\) is the number of classes. During training, the target for each unit corresponding to the sample’s class is set to \(\frac{1}{\omega}\). At test time, the final score for each class is computed as the product of the softmax scores of all units for that class, scaled by \(\omega^\omega\). The authors call this architecture competetitive overcomplete output layer (COOL) and argue that the overcompleteness (many units per class) and competitiveness (units for the same class compete for scores, since the softmax is taken over all of them) drive the architecture to learn many different classifiers per class; the product of the class scores is high iff the sample received a high score from each single classifier. The Spigler, 2017 includes a comparison to the autoencoder method for adversarial examples, and it doesn’t quite live up to the performance of the latter.
The Bayesian Perspective on Uncertainty
Besides this practical approach, there is also a more principled way to define uncertainty in the framework of Bayesian inference. In my experience, this definition of uncertainty is common in the literature. In case you are not familiar with Bayesian thinking, here is a short introduction in terms of neural networks: A Bayesian neural network (BNN) doesn’t have a specific fixed value for each of its parameters (e.g. the weights in its layers), but a distribution of possible values. To get started, we need to express our prior belief over what are reasonable values for the weights by choosing an appropriate distribution (given by its density in our case, denoted as \(p(w)\)). For example, we could believe that all weights are independent (they definitely aren’t!) and follow a Gaussian distribution with mean 0 and standard deviation \(10^{-3}\). This leads to a BNN with a Gaussian distribution placed over each weight, or a product of Gaussians over all weights (since they are assumed to be independent).
During training (usually called inference in the Bayesian setting), we confront our BNN with the training data and update our beliefs about the weights to better reflect the training data (there are various algorithms that do this, but they are usually not as intuitive as SGD). This updating yields a new distribution over the parameters of your model3, the posterior distribution/belief. This posterior is computed according to Bayes rule (in terms of the probability density): \[ p(w\mid x) = \frac{p(x\mid w) p(w)}{p(x)} \] This is to be read as: The probability \(p(w\mid x)\) of a specific weight value \(w\) given the data \(x\) is the product of the prior probability for that value \(w\) and the likelihood \(p(x \mid w)\) of the data given this value for the weight, divided by some constant \(p(x)\) that is independent of \(w\)4.
To get predictions from a BNN after training, you could for example draw many samples from the weight distribution to get different manifestations of the BNN as a regular neural network and average their predictions, if this makes sense for your problem domain5.
Uncertainty and Risk
Uncertainty in this context is simply the variance of the posterior distribution. It essentially describes how certain you are about the values of the parameters of your model. The extreme case of zero variance is a Dirac-distribution that places all its mass on a single point and says that you are absolutely certain of the value for the parameter. Let’s be more precise and call this parameter uncertainty.
You would usually expect that after some iterations of training you get a better and better idea of what the actual values for your parameters are, so their posterior variance decreases and so does your parameter uncertainty. In the limit, you would actually expect the posterior to concentrate around the maximum likelihood estimate for your parameter6.
Note that parameter uncertainty does not capture how likely your model is to make a misprediction: Imagine a simple regression model \(f_w(x) = w\) that ignores its input and outputs the constant \(w\). Take \(w\) as the only parameter of the model and place a Dirac-distribution with value 0 on it, i.e. a distribution that places all its mass on a single value, zero. This is effectively the same as a model without parameters where \(w\) is treated as a constant, since prior and posterior will always be equal (note that, by Bayes rule, if the prior is 0 at a point, so is the posterior). Hence, the parameter uncertainty of this model is 0 yet its performance can be arbitrarily bad.
As another example, consider the problem of predicting the result of an idealized coin toss. The perfect model for this is a Bernoulli distribution with a parameter \(q\) that gives the probability for landing heads. In a Bayesian setting, we first place a prior on \(q\). For example, it might be reasonable to assume that the coin is fair, so the prior should place most of its mass near 0.5, but also spread out over the rest of \([0, 1]\). After a few thousand coin tosses, we probably have a fairly good idea of what \(q\) should be, reflected by the fact that we have a posterior that concentrates around the true value of \(q\) and has a low variance. Thus, by observing many trials parameter uncertainty was reduced greatly (it will in fact go to zero in this case), but that again doesn’t mean that the model doesn’t make any mistakes with its predictions. In fact, the underlying process is stochastic in its nature, so we cannot hope to ever get a model with perfect accuracy7.
So besides parameter uncertainty, there are at least two other factors that determine whether you should trust your model:
- In the first example, the problem was that the model class we chose (given by its architecture and parameter ranges) didn’t contain the true model of the process; let’s call this a model mismatch (not sure whether this is a standard term). If that is the case, zero uncertainty might mean that you have chosen good parameters, but not that you should put any trust into your model.
- In the second case, we have a perfect model of the underlying process, but that process was stochastic to begin with and even the best model runs a risk of making mistakes; let’s call this the risk associated with the task8 (this is a standard term).
The error due to a model mismatch can be reduced by choosing a large class of models – like a deep neural network. It is of course unlikely that this completely eliminates that error source, because the true process generating the data can be as complex as you can imagine. What error remains is either due to suboptimal parameter values (i.e. attributed to parameter uncertainty and manageable by feeding more and more data to the system) or the inherent risk of the task.
One could argue that it doesn’t matter what exactly is the cause for errors made by the system, since measuring the total error on the test set gives a good idea of how much to trust the model, but this is again only on the data that we already have; what the model is predicting for out-of-distribution data might still be very different.
Parameter uncertainty (a property of the model) can be translated into predictive uncertainty for each single data point: Sample many parameter values from the posterior, use these to classify the data point, and look at the resulting distribution of predictions. Its spread is just the predictive uncertainty. Clearly, if the parameter uncertainty of a model is low, so will the predictive uncertainty be. But the converse doesn’t hold, since even fairly different parameter values can yield the same prediction for a data point (i.e. the Bayesian inference process already nailed the probable parameters down to a set where a particular subconcept has already been learnt).
Thus the predictive uncertainty of a datapoint may be used as an indicator of how determined the model’s prediction is for this datapoint. If the model is flexible enough, a low predictive uncertainty should imply that prediction errors on this datapoint are because of the inherent risk of the task. Conversely, high predictive uncertainty means that we shouldn’t trust the model on this datapoint. So this is what we want after all!
Monte-Carlo Dropout and Friends
Great, problem solved! Except that I didn’t mention a concrete way to actually perform the Bayesian inference. For small models and nice priors, you can do this explicitly. For slightly larger models, you can use frameworks like PyMC that make heavy use of sampling-based techniques. For even larger models, you can take a look at Edward. These are all general purpose libraries for probabilistic programming and Bayesian modeling, not necessarily specific to deep neural networks.
One straight-forward approach to get an approximation to predictive uncertainty is to consider an ensemble of classical models as in Lakshminarayanan et al. and looking at the predictive distribution of that ensenmble. This of course requires training multiple models. Another approach that has gotten a lot of attention is from Yarin Gal’s PhD thesis, where he argues that DNNs trained with SGD and ample use of dropout actually perform an approximation to Bayesian inference in a certain sense (using variational inference, a topic for another day). To get the predictive uncertainty for a given datapoint, just use your DNN but still use dropout: Sample 50-100 dropout masks and run the network as often and you will get an empirical approximation of a posterior predictive distribution from which you can calculate a measure of predictive uncertainty. This method is referred to as Monte-Carlo Dropout (MC dropout). Take a look at Gal & Ghahramani, 2015 for the details, like what kinds of priors this procedure corresponds to. I am not going to claim that I fully understand every detail of their metholodgy and I could only explain it with a lot of handwaving (…not that this post is anything but a lot of handwaving) and that is one reason why I am reluctant to recommend it as a method to get some measure of predictive uncertainty (and if you still consider doing it, read all of Yarin Gal’s paper on that topic because there are some caveats to keep in mind, like how good this approximation to the risk is).
The other reason for my reluctance is that I am not alone in not understanding it: A short paper that I haven’t really seen any meaningful discussion of is Osband 2016, where Ian Osband from DeepMind notes that for a very simple example DNN the predictive uncertainty as computed by MC dropout does not decrease with more data. In other words, the predictive posterior does not concentrate even in the limit of infinite data! That’s something that at least I find troublesome for such a simple example and makes me doubt whether that’s actually a good approximation to a Bayesian posterior. Ian Osband’s note actually suggest that what you get from MC dropout is an approximation to risk, not to uncertainty. At the very least, this is a clear signal that one should not simply use MC dropout without any second thoughts. If Yarin Gal’s arguments are correct (and I don’t really doubt that they indeed are), then there seem to be some underlying assumptions that need to be made much much more explicit.
A Conclusion
Phew! To be honest, that last paragraph is the main reason why I wanted to write all of this. I don’t think that there is a single good tool available right now that I can seriously recommend to any practioneer to get any kind of useful estimate of whether to trust your model. In the end, the best advice I can give is to continue doing what you are (hopefully) already doing: Collect more data and ensure that your data faithfully represents the distribution that your system will be confronted with in the wild. Test your systems with such data and use these results to judge your system. That seems to be the best we can reliably do right now.
-
Of course the network’s outputs outside of the distribution that your network thinks your training data represents are constrained in some way, but: The networks usually considered have the capacity to learn so much more than what you actually ask from them (Zhang et al., 2016) and that flexibility means that they are able to do the wildest things outside of your training data. Furthermore, if adversarial examples show anything, then that we generally have a very poor idea of what neural networks actually think your training data represents. ↩
-
Contrast this with the discussion in Bendale & Boult, 2015 where they explicitly say that thresholding is insufficient. The applications considered there are somewhat different though: Bendale & Boult explicitly talk about fooling images and adversarial examples, whereas these latter papers ignore such security aspects. Ironically, the Bendale & Boult paper does not discuss how their network performs on adversarial attacks targeted at their modified network instead of the original one. ↩
-
I am going to be a bit sloppy about what model means. In a non-Bayesian setting, a model is an architecture plus concrete values for the parameters. In a Bayesian setting, a model is an architecture plus a distribution over the parameters; it hence defines a distribution over non-Bayesian models, which is what I mean when I speak of a model class. I may not always point out whether I am using the term model in the Bayesian or the classical sense. ↩
-
I swept this normalization constant under the rug, but there are two things to note about it: First, despite its notation \(p(x)\) it does not represent your prior belief of how probable this particular data point is. The notation hides that the value of this term depends on the class of models under consideration. Specifically, it represents the expected likelihood of the datapoint with the expectation taken over the parameters: \(\int_{v} p(x \mid v) dp(v)\). Secondly, this constant is notoriously hard to compute and the main reason why Bayesian inference is difficult. ↩
-
Instead of averaging the results, it is good practice to look at the distribution of results that you get, as this holds much more information than just a mean value. ↩
-
This assumes that your prior on the parameters satisfies some niceness conditions. ↩
-
In the real world, you could argue that by taking very precise measurements you may in theory be able to predict the outcome of a toin coss with perfect accuracy. But that’s why I consider an idealized coin toss. ↩
-
The notion of risk also makes sense in a non-Bayesian context; it is closely related to the error of a Bayes-optimal classifier ↩