This is an opinion-piece; it comes mostly from my experience with software. If you have any ideas how to test my hypotheses rigorously, please do get in touch. As a bit of context for the following, assume a shared codebase with multiple projects running over multiple (5-10) years that each depend on that shared codebase (think internal game engine plus some games). Let me also state that I agree that code is broken all the time everywhere (at least to some degree), that there is always too much to do for too little time, and that it is pointless to ask people to write perfect code; shipping features is more fun that trying to nail the philosophically ideal form of the code (whatever that may mean), and making money and creating business value is something that I deeply care about. Also, probably none of this is new and shouldn’t be treated as gospel. Good? Good!
Engineering for Change
It is my belief and experience that all useful software is undergoing change on some level, mostly because the requirements change. It is part of the business and a reality that you have to accept. I also believe that I am not the first person to have that clever thought, so it seems very reasonable to assume that the tools other people have successfully employed in the past to build software are at least in part to deal with change.
In order to better understand what challenges change creates for a codebase, I find it helpful to think about the different ways a codebase can change: Adding code, deleting code, modifying code. I conjecture that the act of adding code (for some fixed amount of effort that you are willing to put in) is much more likely to succeed than that of modifying existing code, where succeeding might mean creating a new feature, fixing a bug etc. in a way that does not break existing behavior. By adding code, I mostly mean adding new entities (functions, types, modules etc.) to the codebase and hooking them in. Adding, say, a function to an interface, abstract class, or base class is a modification of existing code, as is changing function parameters, changing a system to perform a job it didn’t do before etc. As an approximation, you could consider removing code instead of modifying code, because the cost of modifying code is bounded by first removing it and then adding the new version (generally not a tight bound, of course).
What are the consequences? Well, the easiest way to add features then is to simply pile on. Once the code is in, it will become harder to change, so it seems reasonable to assume that the initial quality is generally what you are stuck with, unless you invest a great deal of effort later on. Fixing bugs and smaller changes will require modifications and possibly be more difficult. There are plenty of reasons why this asymmetry between adding and removing exists, e.g. that you have fewer constraints when adding code than when modifying and these constraints (chiefly: how to integrate with existing code and not break it) are knowable, at least in principle: Untangling a string is usually harder than tangling it up in the first place.
To me, everything you do to arrange yourself with this asymmetry is an act of software engineering. Some approaches might try to make it easier to change code, others try to reduce the number of cases when you actually have to change a piece of code. Conversely, if some practice is aimed at making it easier to add code, I immediately grow skeptical: The goal should rather be to make it easier to remove code and to react to changes - at the cost of making it harder to add new code.
The exact ratio that you are aiming for these trade-offs of course depends on what kind of code you are writing. I frequently return a diagram such as this one to explain what I mean:
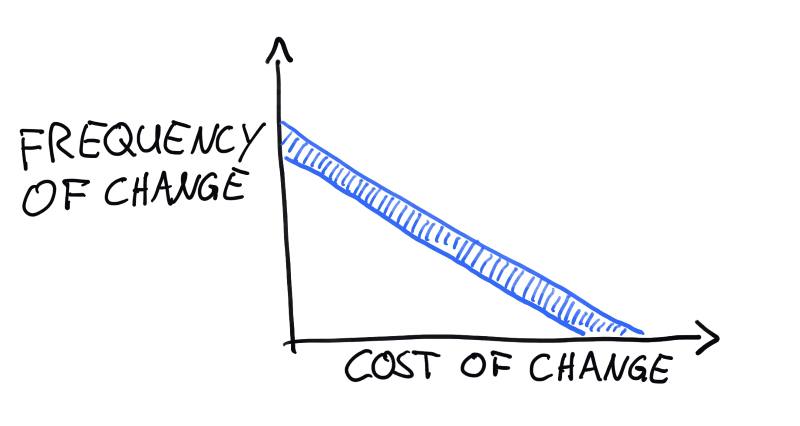
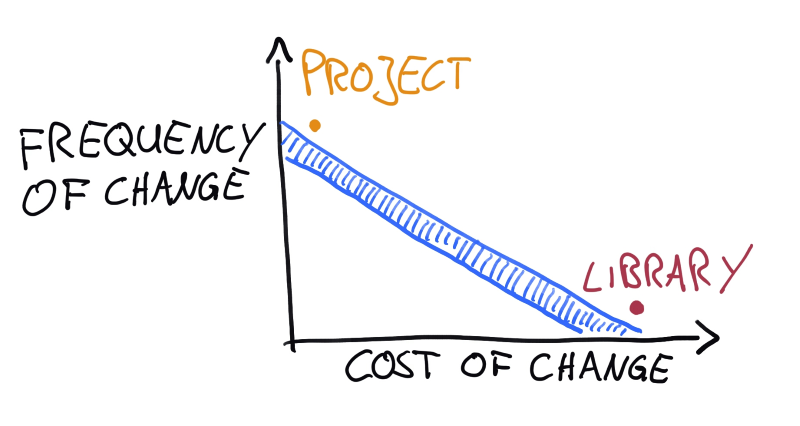
This is a graph showing the frequency of change vs. its cost. The blue strip along the diagonal is where you usually want to be. I do not have any hard numbers on any of this, so the fact that it is a straight line is really arbitrary and depends on the scaling of the axes. The important bit is more that there are lines of equal total cost: Frequent cheap changes are as expensive as infrequent expensive ones. If a component is far above the line, you are wasting money in the future1; if it is far below the time, you are wasting money in the present since you could probably be moving faster. As a general rule of thumb, shared library code is what should be on the far right end of that line, project code is what you should find on the far left end.
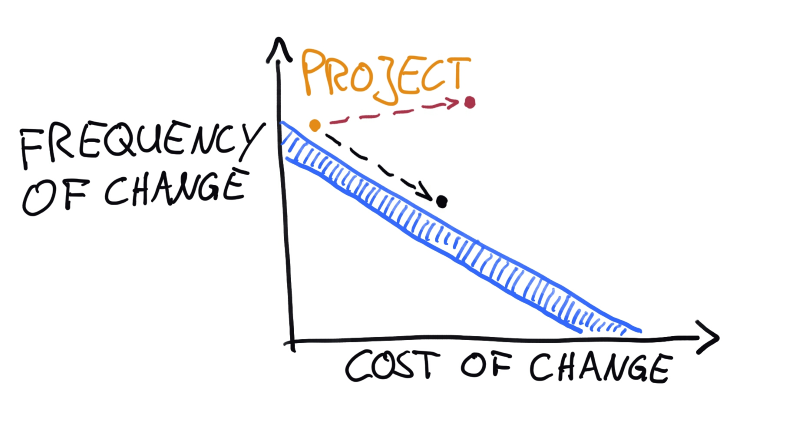
Movement along the line essentially means this: When you make a component harder or costlier to change, you should also make sure that change is less frequent.
What happens when a component is moved from a project into a shared library (in my experience) is usually this: Two projects solve a somewhat similar problem, so the solution is extracted and put into a shared library to “reduce code duplication” or because “it might be useful in the future.” Then the requirements of the projects change independently and it becomes clear that the solution needs to be changed to support more special cases that are only used by one of the projects. The problems they were both solving were only similar by accident and probably lacked an explicit definition to begin with. The result is a complex mess (costly to change) that needs to accomodate the needs of multiple consumers that each have their own idea of what the code should be doing (frequent change). They probably treat it similarly to how it was when it was a solution local to their project, going ahead with that “I’ll just add this over here” mentality that gives birth to functions with 3 bool-typed arguments. Nobody considered the future of cost of change when the component was moved, as if reducing code duplication by itself had any value. What should have been a move to the lower-right in the chart turns out to actually go towards the upper-right.
A similar problem comes up when someone suggests making a solution “more generic.” This usually means that you make the code harder to change and harder to reason about (templated code, anyone?): To no-one’s surprise, a less-well defined problem is in fact not easier to solve than a concrete one. Also, the goal usually is to use the same code in a few places, so “more generic” usually implies more dependents. At this point you need to ensure that you can reduce the frequency of change greatly. It is easy to underestimate the cost of turning something into shared code: Project code can die at some point, it has a very bounded scope. Shared code can potentially never be removed, might amass dependents that are impossible to keep track of (public APIs!), and might at some point become next to impossible to change. Going from one dependent to two does not just make matters twice as difficult; it can be the difference between “oh, let’s delete it” and “I guess it’s staying with us for another 15 years.”
These pains about change can be lessened by not sharing code that you know will change: A class like std::vector solves a problem that you can describe in the abstract; it probably won’t change. Your LoadingScreen class on the other hand probably will change between projects. If you want to share something then design it consciously and document the design decisions (writing proper commit messages is a good start). Make sure that potential users understand what problem the shared code is solving and that there is a cost to changing it. Adding tests to signpost the expectations towards the code might be a helpful way to do this. Try to communicate to potential users that if this code does not solve their problem exactly it might be a stupid idea to shoehorn it into your code and turn something that solved one problem really well into a poor solution for a whole bag of problems.
It might seem that adding documentation and tests makes it even harder to change, and I guess that is true to some extent. The point I’m trying to make is that shared code should ideally be defined by what it is doing, not by where it is used. Code that is defined by its behavior (which implements the solution to some fixed problem) must not change because the problem it solves can not change. This might sound like a philosophical point, but: Problems do not change. You might have a different problem now, but the old problem still exists – similarly how the number 4 does not change into the number 5, you simply have a different number now. If your relationship to the piece of code in question is best described as “I have a different problem now, I’m going to change the code”, then be careful about sharing it. For shared code, you ideally want “I have a different problem now, guess I need to stop using this code” (and ensure that everyone treats it this way)2. Of course this is a simplification and you will probably find a spectrum of this in reality.
TL;DR: It is generally harder to change behavior than to new behavior. Trade-offs that make adding easier on the cost of making change harder are often counter-productive. Sharing code makes change even harder. Code should be shared on purpose and only when you can very clearly articulate what problem it is solving. Shared code is hard to change and should thus be intentionally designed, tested, and documented to ensure that the expectations towards it are clear.